Perito criminal - Área 1: Contábil-Financeira - 2025
Em um modelo de regressão linear simples, foi observado que y = 2+ 2x + ∈, em que y representa a variável dependente, cujo desvio padrão amostral é igual a 6, e x denota a variável regressora, cuja média e desvio padrão amostrais são, respectivamente, iguais a 5 e 2,4. O termo ∈ representa o erro aleatório com média zero e variância 4. A partir das informações apresentadas na situação hipotética precedente, considerando que esse modelo foi obtido pelo método de mínimos quadrados ordinários, julgue o seguinte item.
A correlação linear de Pearson entre as variáveis x e y é igual a 0,8.
Em um modelo de regressão linear simples, foi observado que y = 2+ 2x + ∈, em que y representa a variável dependente, cujo desvio padrão amostral é igual a 6, e x denota a variável regressora, cuja média e desvio padrão amostrais são, respectivamente, iguais a 5 e 2,4. O termo ∈ representa o erro aleatório com média zero e variância 4. A partir das informações apresentadas na situação hipotética precedente, considerando que esse modelo foi obtido pelo método de mínimos quadrados ordinários, julgue o seguinte item.
A média amostral de y é igual a 10.
Durante um processo de ETL, um arquivo JSON contendo objetos aninhados foi carregado diretamente em banco de dados que suporta tipos JSON nativos sem qualquer transformação ou modificação na estrutura dos dados. O objetivo dessa operação foi preservar a estrutura original do JSON para consultas e análises. Com base nessa situação hipotética, julgue o item a seguir.
No caso relatado, a integridade da estrutura hierárquica dos dados permite consultas específicas em níveis profundos do documento.
A respeito da análise exploratória de dados (AED), julgue o item seguinte.
Observe os dados da tabela a seguir.
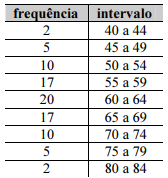 Com base nas informações da tabela, relativas à variável aleatória X, é correto afirmar que a função densidade dessa variável tem características consistentes com a distribuição normal.
Com base nas informações da tabela, relativas à variável aleatória X, é correto afirmar que a função densidade dessa variável tem características consistentes com a distribuição normal.
A respeito da análise exploratória de dados (AED), julgue o item seguinte. A AED deve ser concluída antes da modelagem estatística ou do aprendizado de máquina, de forma a não interferir, com redirecionamentos ou revisões interpretativas, no processo posterior.
A respeito das regras de associação e da análise de agrupamentos na exploração de dados, julgue o item subsequente.
O algoritmo k-means é um método de clusterização do tipo particional que requer a definição prévia do número de clusters e utiliza a média dos elementos como critério para a atualização dos centroides.
A respeito das regras de associação e da análise de agrupamentos na exploração de dados, julgue o item subsequente.
O algoritmo FP-Growth é mais eficiente que o algoritmo Apriori.
No que se refere a processamento de linguagem natural, árvores de decisão e Python, julgue o item que se segue.
Considere que um algoritmo de árvore de decisão utilize entropia como medida de impureza para realizar as divisões dos dados em diferentes nós da árvore. Considere ainda que a entropia seja máxima quando a distribuição das classes é perfeitamente equilibrada e mínima quando todos os exemplos pertencem a uma única classe. Nesse caso, em uma partição contendo 100 exemplos classificados em três categorias A, B e C, a entropia da partição é maior no cenário em que há 33 exemplos de cada classe do que no cenário em que há 90 exemplos da classe A, 5 da classe B e 5 da classe C, mesmo que o número total de exemplos na partição seja o mesmo em ambos os casos.
No que se refere a processamento de linguagem natural, árvores de decisão e Python, julgue o item que se segue.
O modelo BoW ( bag of words ) é capaz de capturar relações sinonímicas entre palavras.
No que se refere a processamento de linguagem natural, árvores de decisão e Python, julgue o item que se segue.
dados = [3, 7, 0, -1, 7] resultado = {} for i in range(len(dados)): if dados[i] > 0: chave = f”v_{i}” if dados[i] not in resultado.values(): resultado[chave] = dados[i] else: resultado[chave] = -dados[i] elif dados[i] == 0: continue else: resultado[f”neg_{i}”] = abs(dados[i]) print(resultado) A execução do código Python precedente resulta no trecho a seguir. {'v_0': 3, 'v_1': 7, 'v_3': -1}