Analista Judiciário - Ciência de Dados e Analytics - 2024
Um time de futebol disputa um campeonato em que joga um número igual de partidas em seu estádio e fora de seu estádio. As probabilidades de ganhar, empatar ou perder uma partida quando joga em seu estádio são, respectivamente, 1/2, 1/5 e 3/10. As probabilidades de ganhar, empatar ou perder uma partida quando joga fora de seu estádio são, respectivamente, 1/5, 1/5 e 3/5.
Um torcedor desinformado, ao chegar em sua aula sobre inferência bayesiana, ouviu de seus amigos que o referido time havia perdido a última partida que disputou. Sem obter nenhuma informação adicional, o torcedor resolveu calcular as probabilidades (a posteriori) de o time haver jogado a última partida em seu estádio ou fora de seu estádio.
As probabilidades calculadas corretamente pelo torcedor foram, respectivamente,
A ingestão de dados consiste na coleta, importação ou transferência de dados para um sistema de armazenamento e processamento. Em geral, a ingestão de dados representa o primeiro passo em um pipeline de processamento. Os dois principais métodos de ingestão de dados são a ingestão em lote (batch) e a ingestão em tempo real (streaming).
A respeito desses métodos, avalie as afirmativas a seguir.
I. A ingestão em lotes se dá continuamente ao longo do tempo e é utilizada quando há necessidade de se processar os dados imediatamente após sua coleta.
II. A ingestão em tempo real incorpora novos dados em massa, em intervalos ou blocos periodicamente transmitidos da fonte para o dispositivo em que ocorre o processamento.
III. Em ambos os métodos, é comum que os dados sejam transformados e validados, garantindo-se assim a precisão e a consistência das informações ingeridas.
Está correto o que se afirma em
O processamento MapReduce consiste na aplicação de um algoritmo de computação distribuída para processar grandes conjuntos de dados em um cluster de computadores, dividindo cálculos complexos em tarefas menores e que podem ser executadas em paralelo. O MapReduce é implementado em etapas. Em uma dessas etapas, os dados de entrada divididos em partes são transformados em conjuntos de pares chave-valor (i.e., key-value pairs) adequados para o processamento paralelo e distribuído.
A essa etapa do MapReduce dá-se o nome de
Modelos de linguagem de larga escala (Large Language Models - LLM) são frequentemente utilizados em processamento de linguagem natural, e podem gerar resultados inesperados em resposta às consultas dos usuários. Essas respostas são chamadas de alucinações dos modelos. Uma técnica usada para se evitar tais alucinações consiste em combinar os modelos generativos com sistemas de recuperação de informações, permitindo buscas em bases de dados mais confiáveis e melhorando a qualidade das respostas geradas.
A essa técnica dá-se o nome de
A Analista Judiciária Bianca, ao verificar um conjunto de dados, identificou que alguns valores não eram condizentes com o domínio definido para aqueles dados, de acordo com o DAMA-DMBOK.
Assinale a opção que apresenta a dimensão da qualidade de dados mais afetada nesse caso.
De acordo com o DAMA-DMBOK, 2ª edição, com relação à qualidade de dados, avalie as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) A qualidade de um dado depende em se atender às necessidades e expectativas daqueles que consomem esse dado. Dessa forma, a qualidade de um dado depende do contexto e necessidade dos consumidores desse dado.
( ) Ao analisar um determinado conjunto de dados, um Analista pode utilizar o Data Profiling para inspecionar dados e melhorar sua qualidade, corrigindo problemas. Exemplos de procedimentos compreendidos pelo Data Profiling incluem a identificação e remoção de outliers, assim como valores duplicados e a adição de atributos como Time/Date stamps.
( ) Data Enhancement, ou simplesmente enriquecimento, consiste em aprimorar um conjunto de dados existentes, para aumentar sua qualidade e usabilidade. Esse aprimoramento deve utilizar exclusivamente fontes internas à organização, uma vez que essas são consideradas mais confiáveis do que fontes externas.
As afirmativas são, respectivamente,
A computação em nuvem permite armazenamento, processamento e acesso flexível a dados e aplicações remotamente.
Sobre os conceitos envolvidos na computação em nuvem, é correto afirmar que
Regtechs e Suptechs têm se destacado como grandes tendências no sistema financeiro. Com a modernização do setor e o crescimento das fintechs, o mundo tem presenciado uma série de transformações regulatórias para acompanhar e fomentar essas inovações.
Nesse contexto, analise as seguintes afirmações sobre Regtech e Suptech.
I. Suptech é voltada para as autoridades reguladoras, permitindo monitorar em tempo real o mercado e as instituições financeiras. Com o uso de big data e análise preditiva, essas tecnologias ajudam a identificar riscos, prevenir crises e garantir a estabilidade financeira.
II. O Suptech é voltado tanto para as autoridades reguladoras quanto para as empresas, com o objetivo de aprimorar a supervisão dos sistemas, aumentando a eficiência no monitoramento de transações e na detecção de fraudes.
III. As soluções de Regtech se concentram exclusivamente na gestão de dados e riscos das empresas, sem abordar aspectos relacionados a compliance ou a geração de relatórios regulatórios.
Está correto o que se afirma em
Os outliers são dados que se distinguem significativamente dos demais no conjunto. Um outlier é um valor que se desvia substancialmente da normalidade e pode causar anomalias nos resultados gerados por algoritmos e sistemas de análise.
A seguir, é apresentado um gráfico de boxplot, que ilustra os retornos mensais das ações de uma empresa
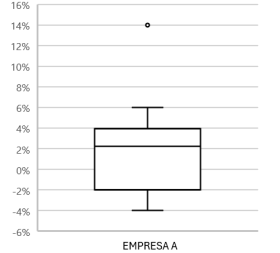
Nesse contexto, analise as seguintes afirmações.
I. Outliers nunca devem ser removidos, pois sempre carregam informações importantes e não têm a capacidade de distorcer resultados ou enviesar modelos de análise.
II. A partir da análise visual do boxplot apresentado, é possível afirmar que o valor 14% é um outlier, pois ele está visivelmente distante do corpo principal dos dados, fora do intervalo interquartil (IQR).
III. Para a detecção de outliers, além da identificação visual, é possível utilizar métodos estatísticos e técnicas baseadas em aprendizado de máquina.
Está correto o que se afirma em
Considere as linhas de código a seguir, que foram escritas na linguagem de programação Python (versão 3.10.12), com utilização de NumPy (versão 1.25.0).

Com relação à execução da linha <4>, assinale a afirmativa correta.